



















Build and Scale Reliable Applications Faster



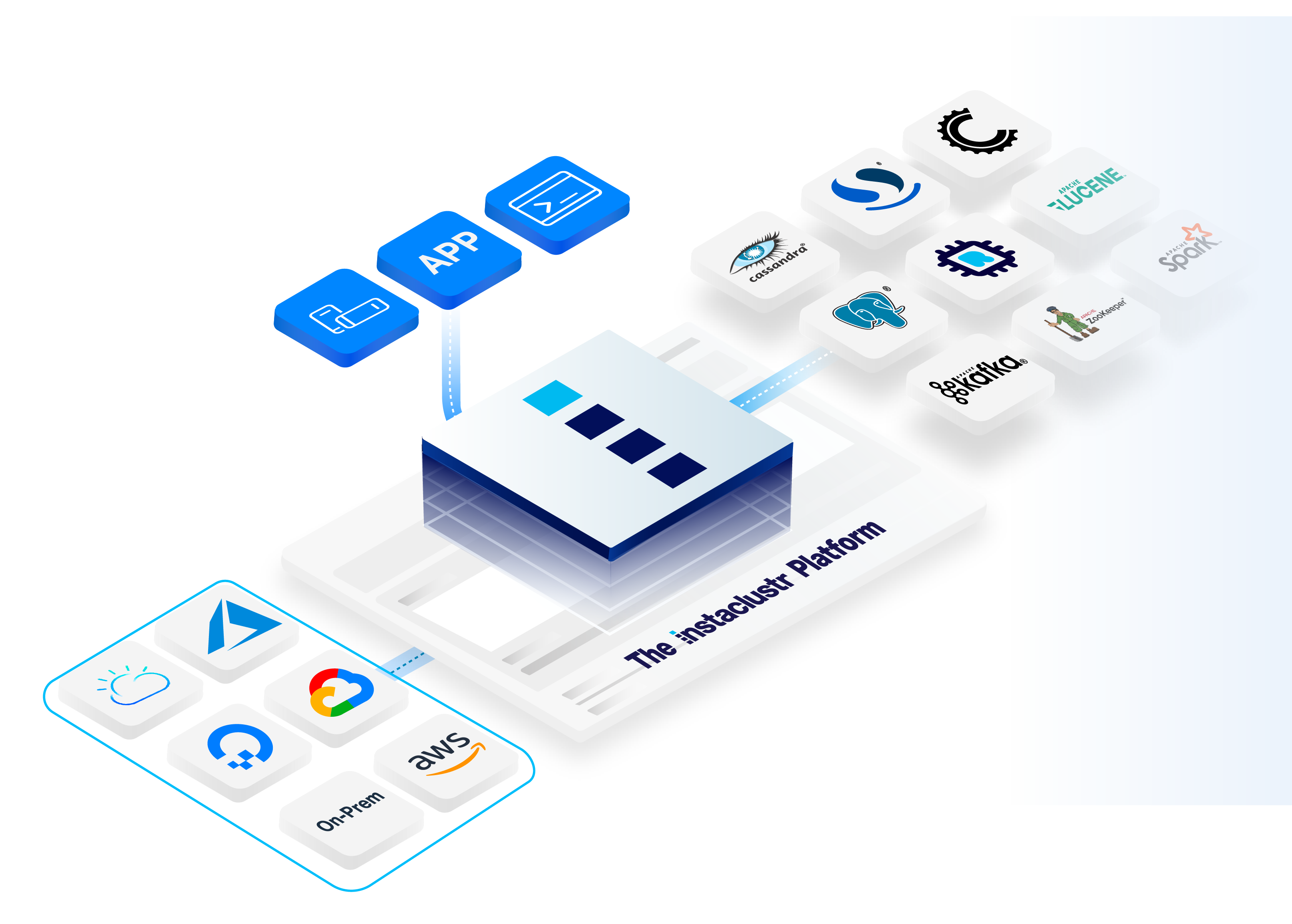
What We Do
Instaclustr operates open source databases in the cloud. We have curated the most scalable and popular open source technologies, and developed SaaS offerings so that you benefit from self-service access in minutes.
We have a global team of expert consultants and a global support team that operates our SaaS platform. Our Support team also provides 24x7x365 support services for any of the technologies that we offer on our platform.
The Instaclustr Difference
-

 100% Open SourceInstaclustr only offers true open source solutions. We’ll never charge you license fees or lock you in with complicated contracts.
100% Open SourceInstaclustr only offers true open source solutions. We’ll never charge you license fees or lock you in with complicated contracts. -
 Transparent PricingYou’ll have clear pricing from the start based on your node size, cloud choice or on-prem environment, region, and any add-ons.
Transparent PricingYou’ll have clear pricing from the start based on your node size, cloud choice or on-prem environment, region, and any add-ons. -
 Multi-Tech Data PlatformWhat makes us unique is our comprehensive suite of technology solutions for all of your data needs. We also offer full project lifecycle capabilities and our unrivaled service levels.
Multi-Tech Data PlatformWhat makes us unique is our comprehensive suite of technology solutions for all of your data needs. We also offer full project lifecycle capabilities and our unrivaled service levels.
Performance Testing PostgreSQL® on Azure NetApp Files


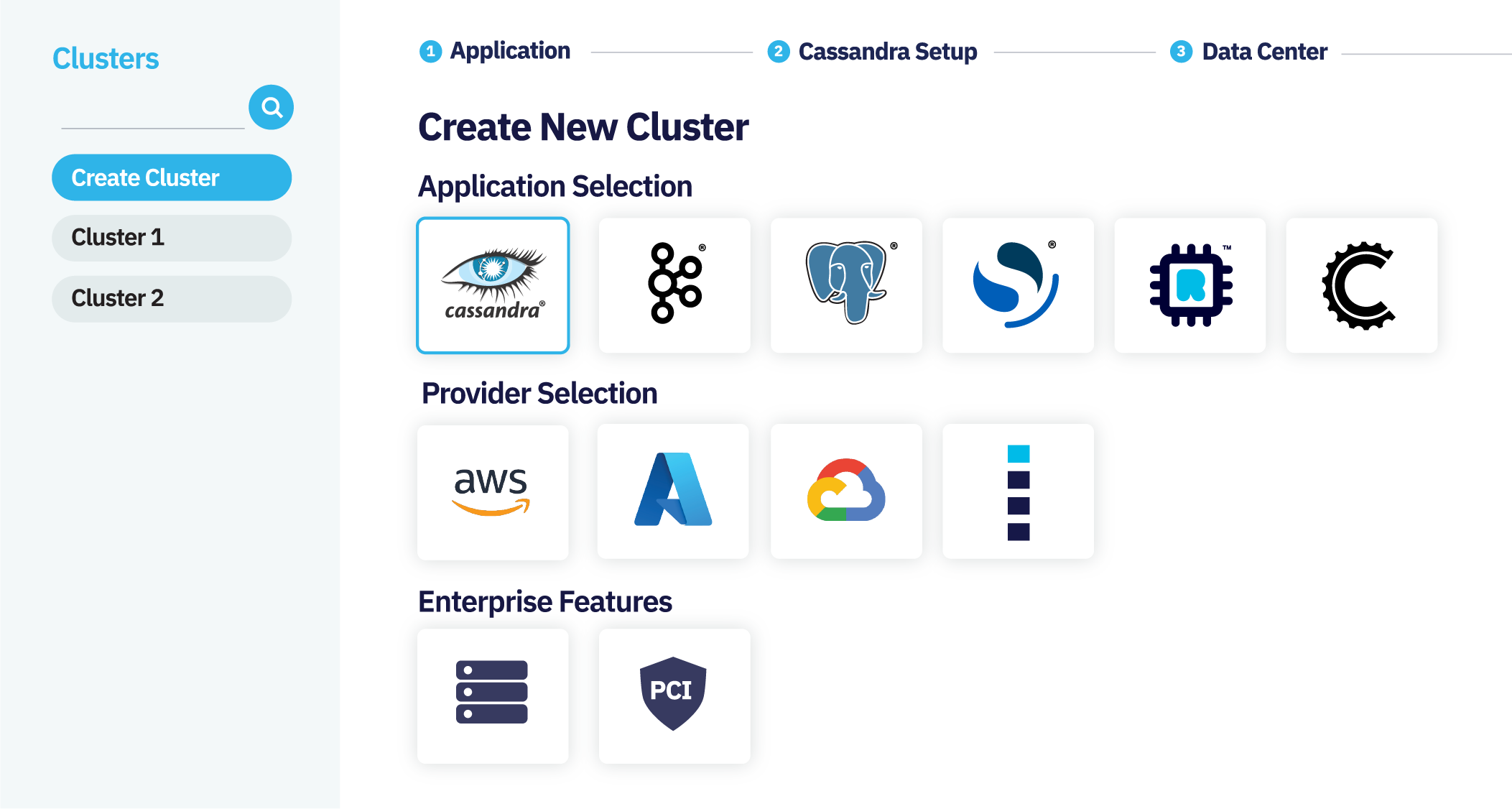
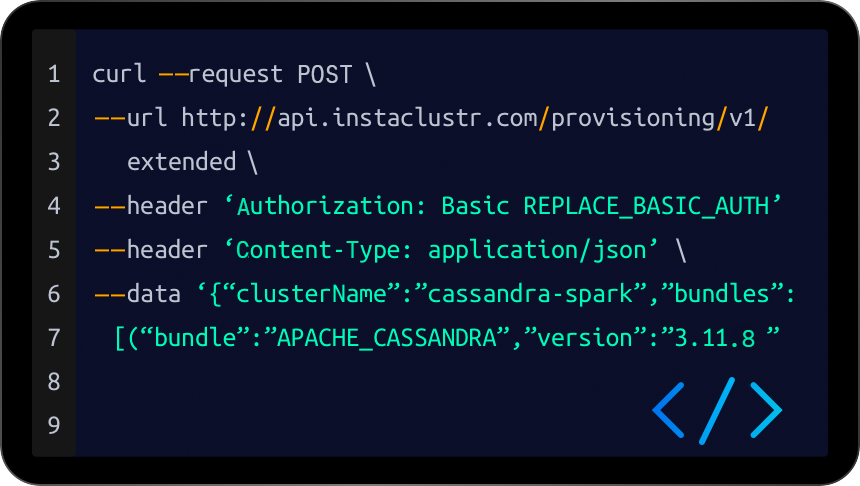
Deploy a Cluster in Minutes

Most Experienced Open Source Team
- 300M+Node hours under management
- 24x7Support
- 9+Petabytes under management




Featured Resources
Read All-
- White Papers
Understanding Cadence Workflow for Developers and Architects
Cadence is an open source technology that underpins the architectures of several leading technology organizations.
-
- Press Release
Instaclustr Ranks as One of the Fastest-Growing Companies in North America on the 2021 Deloitte Technology Fast 500™
As demand for open source data infrastructure solutions continues to accelerate, Instaclustr sees rapid growth from organizations seeking to build and scale their applications faster and more cost-efficiently REDWOOD CITY, Calif – November 17, 2021 – Instaclustr, which helps organizations deliver applications at scale by operating and supporting their open source data infrastructure, today announced…
-
- PostgreSQL
Instaclustr Announces PostgreSQL® on Azure NetApp Files Storage
One year ago, NetApp announced the acquisition of Instaclustr to “move up and shift left”–meeting the needs of developers by providing a PaaS that brings together the application management, optimization, and compliance services that organizations need to achieve speed to market, agility, and cost-effectiveness in the cloud. Today, we announce a major step towards realizing…